


免费MT5平台:使用政策梯度算法为交易助力
在动态市场环境中,强化学习模型的过拟合问题与策略优化挑战尤为突出。传统Q函数近似方法在面对无限变化的市场状态时,容易因环境动态性导致策略失效。本文结合政策梯度方法,探讨其在解决模型过拟合与探索-利用平衡中的优势,并通过免费MT5平台实现策略部署的可能性。

一、强化学习中的过拟合与市场环境特性
强化学习模型通过代理者(Agent)与环境的交互学习最优策略,其核心目标是通过Q函数近似最大化累积奖励。然而,在金融市场中,状态空间呈现高度非结构化和动态变化特性:
1. 状态不可重复性:市场没有两个完全相同的状态,相似状态的下一个状态可能完全相反;
2. 奖励政策对抗性:环境可能通过调整奖励机制反制代理者的可预测行为,导致Q函数近似失效;
3. 贪婪策略局限性:选择最大期望奖励的动作虽简化决策,但会降低环境探索能力,加剧过拟合风险。
二、政策梯度方法的核心优势
政策梯度(Policy Gradient, PG)通过直接优化策略函数π(α|s),而非间接优化Q函数,有效应对上述挑战:
1. 策略表示与优化
策略函数π由神经网络参数化,输出动作概率分布。通过最大化累积奖励的期望值,计算策略梯度并更新参数:
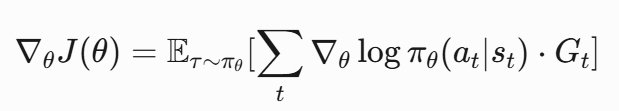
其中,Gt为折扣奖励。相较于Q函数近似,该方法无需依赖值函数估计,避免了因环境变化导致的Q值偏差。
2. 动态环境适应性
随机策略梯度(Stochastic Policy Gradient)通过动作采样引入探索噪声,平衡探索(Exploration)与利用(Exploitation):
-初始阶段:所有动作概率均匀分布,最大化环境探索;
-训练过程中:高盈利动作的概率逐渐增加,形成适应性策略。
这种自适应平衡机制使模型能够应对市场状态的突发变化。
3. SoftMax与概率归一化
神经网络输出层通过SoftMax函数将动作评分转换为概率分布:
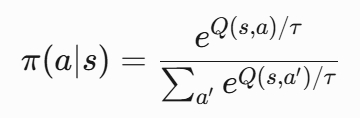
其中,温度参数τ控制探索强度。τ较大时,动作选择更随机;τ较小时,策略趋近贪婪。该机制确保了概率分布的合法性和策略连续性。
三、MT5平台下的策略实现路径
在MT5中集成政策梯度模型需完成以下步骤:
1. 数据准备:将历史K线数据(如开盘价、收盘价、成交量)编码为状态特征,构建状态序列;
2. 模型训练:使用PyTorch等框架实现策略网络(如代码示例),通过历史数据模拟环境交互,优化策略参数;
3. 实时推理:将训练好的模型封装为MT5插件,实时接收行情数据并输出动作概率,通过API执行交易指令;
4. 在线学习:定期用新数据更新模型,适应市场风格转变。
四、改进方向与挑战
尽管政策梯度方法在动态环境中表现优异,仍需关注以下问题:
1. 梯度估计偏差:蒙特卡洛采样可能导致优势函数估计误差,可通过引入基线(Baseline)或使用Actor-Critic框架降低方差;
2. 计算效率:高维状态空间下,神经网络训练成本较高,可结合函数近似(如Fourier特征)压缩状态维度;
3. 市场微观结构影响:需在模型中引入交易成本、滑点等现实约束,避免策略过度拟合历史数据。
政策梯度方法通过直接优化策略函数和动态探索机制,为金融市场的强化学习提供了鲁棒性更强的解决方案。结合免费MT5平台的实时交易能力,该方法有望实现从理论到实践的转化。